

Why Emails Are Powerful Identity Anchors
Think for a moment about your own email address.Maybe you created it back in college. Maybe it’s the one you’ve carried with you through jobs, apartments, relationships, and countless password resets. It’s the login you still use for Netflix, Amazon, LinkedIn — maybe even your bank.
That single string of characters has silently followed you through every corner of the internet. Unlike phone numbers that change when you switch carriers, or home addresses that shift when you move, email tends to endure. It’s the invisible thread weaving together your digital life.
Now flip the perspective. Imagine you’re running a business that needs to trust the people signing up. Each new customer arrives at your digital doorstep with just a few details: a name, maybe a phone number, and always an email. On the surface, those inputs look ordinary. But beneath them lies a treasure chest of signals.
From Mailbox to Identity Anchor
For years, we thought of email simply as a mailbox. Somewhere to send promotions, password resets, or invoices. But that’s a limited view.
In reality, an email is an identity anchor — a persistent identifier that ties together accounts, services, transactions, and histories. Every time a person signs up for a platform, their email leaves a footprint. Connect those footprints, and suddenly you’re not looking at just an inbox. You’re looking at patterns:
- Is this email tied to long-standing accounts across trusted networks?
- Has it shown up in data leaks, suggesting it’s been compromised?
- Does its structure look like a genuine user’s or like a throwaway fraudster’s?
- Is it consistent with the name, phone number, or location the person provides?
These aren’t abstract questions. They’re the difference between catching fraudsters before they slip through and welcoming in good customers without unnecessary friction.
Two Emails, Two Stories
Picture this scenario.
A fintech startup launches a new lending app. Two new users sign up on the same day. Both fill out the form with a name, an income level, and of course, an email.
- User A enters an email that’s been active for over a decade. It’s linked to social media profiles, professional networks, and even a personal Dropbox. The domain is well-established, with secure records in place. No major breaches are associated with it.
- User B submits an address created last week on a disposable service. No social accounts are connected. The same email appears in multiple leaked databases. Its format is suspicious: random numbers and characters that don’t resemble a real name.
On paper, these users look the same. In reality, one is a trustworthy borrower, the other a potential fraud attempt. And the difference is revealed not by expensive background checks, but by the hidden story inside an email address.
What Is Email Intelligence?
Beyond Simple Lookups
For years, the default way of checking an email was a reverse lookup: you enter an address, and if you’re lucky, you get back a name or a profile. Useful, yes — but it barely scratches the surface.
Email intelligence is different. It is the systematic analysis of all the signals connected to an email address, not just the obvious ones. Instead of asking “who owns this email?”, the real question becomes:
- “What can this email tell us about its authenticity?”
- “Does it behave like a trusted user’s email — or like a fraudster’s throwaway?”
This shift in perspective is what makes email intelligence powerful.
A Layered Perspective
At its core, email intelligence works by layering multiple dimensions of analysis:
- Technical Dimension
The infrastructure of the email: is the address valid, active, and properly configured? - Behavioral Dimension
The way the email “looks and acts”: does it resemble natural human patterns or something machine-generated and disposable? - Reputational Dimension
The wider ecosystem view: how is this email regarded in terms of trust, spam, or fraud association? - Historical Dimension
The timeline of the address: how long it has existed, and whether it has appeared in leaks or questionable contexts over time.
When these perspectives are combined, the result is far richer than any one dimension on its own.
Why It Matters
Fraud detection, risk assessment, and even user experience all hinge on knowing who to trust. Traditional identity checks are often expensive, slow, or easy to bypass. Email intelligence, by contrast, works instantly and invisibly at the very first point of contact.
It doesn’t replace KYC or onboarding processes — it strengthens them by filtering out suspicious users before they reach later, costlier stages.
This is what makes email intelligence transformative: it elevates the email address from a static field on a form to a dynamic risk indicator.
Sources of Email Intelligence
Where does email intelligence actually come from? What are the specific sources that reveal whether an email is trustworthy, suspicious, or outright fraudulent?
Think of these sources as the sensors in a security system. Each one captures a piece of the story. No single sensor gives the whole truth, but together they create a clear signal.
- Connected Accounts & Profiles
An email address is the key that unlocks accounts across the internet. Checking where it has been used tells us a lot:
- Social media links: If an email is tied to Facebook, LinkedIn, or Instagram, it suggests a real person is behind it.
- Professional platforms: Appearances on GitHub or Slack show legitimate activity, especially if consistent with the user’s name.
- Cloud and productivity tools: Connections to Dropbox or Google Workspace accounts indicate everyday, long-term use.
Example: An applicant’s email is linked to a LinkedIn profile with a full work history — a strong trust signal. Another applicant’s email has zero associations, suggesting it was created solely for this one sign-up.
- Domain Data
The domain (everything after the “@”) carries vital context:
- Domain age: Fraudsters spin up new domains overnight. A domain registered in 2008 is far safer than one registered last week.
- DNS setup: Proper SPF, DMARC, and MX records suggest the domain was configured with care. Missing records often flag abuse.
- Disposable services: Domains like mailinator.com or tempmail.net are instant warnings.
- Typosquats: Look-alike domains (gmial.com) are designed to trick.
Example: An address ending with @corporate-finance.co.uk that’s been live for a decade signals stability. @quickloan-signup123.com registered yesterday? Much riskier.
- Breach & Leak Databases
Data breaches leave a trail, and that trail can be checked:
- Exposed emails: If an email has appeared in a known leak, it may already be compromised.
- Frequency: A one-time exposure is concerning; multiple breaches paint a more dangerous picture.
- Context of leaks: Breaches from financial services or marketplaces are especially relevant.
Example: A user applies with an email that appears in “Collection #1” plus two other dumps. Even if the account is real, its security is questionable.
- Communication & Deliverability Signals
Before analyzing deeper, it’s worth asking: can this email even receive mail?
- Active or inactive: Nonexistent addresses are immediate red flags.
- Bounce history: Addresses or domains with high bounce rates suggest unreliability.
- Spam traps: Some addresses are planted by security systems to catch bad actors. Appearing here is a strong indicator of abuse.
Example: Two emails look fine on the surface. One is deliverable and active, the other bounces back instantly. Email intelligence catches what the naked eye misses.
- Behavioral & Format Patterns
Fraudsters often leave fingerprints in the way they construct emails:
- Naming conventions: maria.garcia1992@gmail.com looks human; xj9q7zzp001@mail.io does not.
- Digit overload: Too many numbers often signal automation.
- Filler words: Addresses with “test,” “mail,” or “demo” are rarely used for genuine identities.
- Length extremes: Very short or excessively long strings often point to bots.
Example: A marketplace seller signs up with sellfast2025@gmail.com — plausible. Another signs up with a8zq9910xps@mailfast.io — suspicious.
- Metadata & Geographic Indicators
Even without IP tracking, emails provide subtle geographic hints:
- Country codes and timezones connected to registration.
- Regional operators tied to certain domains.
- Cross-checks with other fields: Does the email’s geography match the phone number or stated country?
Example: An email suggests Brazil while the phone number points to Germany. That inconsistency alone doesn’t prove fraud, but when combined with other signals, it raises a red flag.
- Aliases & Cross-Identifiers
Fraud often hides in inconsistency. Checking aliases and overlaps can expose it:
- Multiple names tied to one email: Could suggest synthetic identity.
- Nicknames and variations: Natural if consistent across platforms, suspicious if wildly different.
- Mismatch with declared info: If the sign-up says “John Smith” but the email is linked to “Maria Gonzalez” elsewhere, the system needs to dig deeper.
Example: A loan applicant’s email is tied to three unrelated names across different platforms. That’s a sign of manipulation.
Layering the Sources Together
Individually, each of these sources is just one clue. Together, they create the mosaic of email intelligence.
- New domain + no connected accounts + format like a9x9910@mail.io → High risk.
- Long-established Gmail + multiple linked accounts + no leaks → Low risk.
- Trusted domain + history of breaches + odd alias mismatch → Medium risk, review needed.
This layered approach is what turns email from a trivial login field into a powerful risk indicator.
These sources are the raw data. But how do you make sense of them? That’s where the approaches to analysis come in — the frameworks and methods for turning dozens of signals into one clear picture of trust or risk. We’ll explore those next.
Approaches to Email Intelligence Analysis
In the previous section, we looked at the sources of email intelligence — the raw ingredients. But raw data on its own is just noise. What makes email intelligence valuable is the ability to analyze those signals, connect the dots, and extract meaning.
This is where analysis approaches come in. Think of them as the lenses that sharpen the picture, transforming disconnected clues into actionable insights.
- Validation & Verification
The first step in any analysis is simple: is the email even real?
- Syntax checks catch obvious errors like missing “@” symbols or invalid characters.
- Mailbox verification ensures the address is active and can receive mail.
- Domain verification checks whether the underlying domain is valid and configured.
Example: A fraudster tries to sign up using michael@@gmail.com. A syntax check alone filters them out. Another signs up with loan.approval@tempmail.io — technically valid, but disposable. A deeper verification catches the problem.
Validation doesn’t stop fraud by itself, but it clears away the obvious noise, letting the system focus on more sophisticated signals.
- Reputation & Risk Assessment
Once an email is confirmed valid, the next question is: what kind of reputation does it carry?
- Blacklists and complaint databases reveal addresses and domains tied to spam or abuse.
- Spam traps catch emails used in shady campaigns.
- Fraud signals connect addresses to previously flagged activity.
This step is like checking someone’s references before offering them a job. Past behavior often predicts future risk.
Example: Two users register with addresses that look similar. One comes from a clean domain; the other domain is flagged for high spam rates. Even without further data, the second is immediately riskier.
- Cross-Linking & Enrichment
Fraudsters try to hide behind minimal information. Email intelligence pushes back by expanding the picture.
- Connected accounts: Does this email exist on LinkedIn, Instagram, or GitHub?
- Aliases and nicknames: Does the email appear under consistent identities across services?
- Activity footprints: A real person leaves traces; a burner email does not.
Cross-linking doesn’t just verify identity — it strengthens trust by showing a coherent story.
Example: A new applicant’s email appears on LinkedIn, with a work history that matches the application form. That coherence is a strong green flag. Another applicant’s email has zero external presence. That absence, combined with other signals, suggests higher risk.
- Historical Analysis
An email’s timeline often tells the most powerful story.
- First seen dates show how long the email has existed.
- Breach history reveals whether the address has been compromised before.
- Activity continuity (appearing across multiple years and services) suggests long-term use.
Fraudulent accounts tend to be short-lived. They appear, attack, and disappear. Real identities, by contrast, persist.
Example: One applicant’s email first appeared online in 2007, has social profiles dating back a decade, and no major breaches. Another appeared last week, already linked to a disposable domain. Which one would you trust?
- Pattern Recognition
This is where machines excel. By analyzing the structure and behavior of email addresses, patterns emerge that humans might miss.
- Unusual character strings often point to automation.
- Sequential digits or repeating letters can signal fake bulk accounts.
- Length outliers (too short or excessively long) are often suspicious.
- Naming anomalies (e.g., male name in email, female name in form) highlight inconsistencies.
Pattern recognition turns subtle quirks into clear risk flags.
Example: An account named John Smith signs up with maryjane1995@outlook.com. Alone, the mismatch might be harmless. Combined with other signals (recently created, no social presence), it becomes suspicious.
- Weighted Scoring & Risk Models
Raw signals are rarely binary. A single breach doesn’t automatically mean fraud, just as a disposable domain doesn’t guarantee malicious intent. The real challenge is weighing all signals together.
That’s where risk scoring models come in. These models assign weights to different signals and calculate an overall trust level.
- Low risk: Long history, connected accounts, minimum breaches.
- Medium risk: Some inconsistencies, but not definitive.
- High risk: Multiple red flags — disposable domain, no presence, recent creation, lots of breaches.
The scoring process condenses dozens of raw signals into a single, actionable insight.
Example: A marketplace flags any sign-up with a risk score under 700 (on a 0–1000 scale). One applicant hits 350 (high risk), another 850 (low risk). The platform can confidently accept the first and review or block the second.
- Continuous vs. Static Analysis
Traditionally, email checks were one-time events — performed at onboarding and forgotten. But fraud evolves, and so do signals.
Modern approaches lean toward continuous monitoring:
- Emails that were safe last year may now appear in new breaches.
- Reputation can shift over time as domains are repurposed or compromised.
By treating email intelligence as dynamic, businesses can adapt quickly to emerging risks instead of relying on stale data.
Validation filters the noise.Reputation checks reveal history.Cross-linking shows presence.Historical analysis exposes longevity.Pattern recognition catches subtle anomalies.Risk models unify it all.
Together, these approaches transform an email from a flat string of text into a dynamic risk profile.
Deriving Insights: From Signals to Meaning
After all, businesses don’t just want data — they want insight. They want to know whether to approve a loan application, allow a new account, or prioritize a lead. Email intelligence delivers that by connecting technical signals to human meaning.
From Raw Data to Insight
Imagine an online lender. A new customer applies, and the system gathers dozens of signals:
- Domain age: 2 days old.
- Email format: xy9qqz001@mailfast.io.
- Breach history: Appears in ten leaks.
- Connected accounts: None.
- Deliverability: Active.
Each signal on its own might not be enough to decide. Together, they tell a clear story: this is likely a throwaway email tied to fraud or synthetic identity creation.
That’s insight: the transformation of disconnected facts into a single, actionable conclusion.
The Three Levels of Insight
When organizations apply email intelligence, insights usually fall into three levels:
- Trust Signals
These are positive indicators that suggest the email belongs to a legitimate user. Examples include:
- Old domain with consistent security settings.
- Social and professional accounts tied to the address.
- No breach history or only very minor exposure.
- Natural structure matching the user’s declared name.
Interpretation: The user is likely authentic and safe to onboard with minimal friction.
- Warning Signals
These are mixed indicators — not outright fraudulent, but enough to merit closer inspection. Examples include:
- Mismatch between email name and declared name.
- Breach history in lower-risk platforms (e.g., old gaming forums).
- Recent domain, but not disposable.
- Limited digital presence.
Interpretation: The user might be genuine but could require secondary checks (e.g., ID verification).
- Red Flags
These are strong negative signals that usually justify rejection or high scrutiny. Examples include:
- Disposable or temporary domain.
- Appearance in multiple high-risk breaches.
- Zero connected accounts.
- Spam trap or abuse association.
- Abnormal structure (e.g., random strings, excessive digits).
Interpretation: The account is likely fraudulent and should be blocked or escalated.
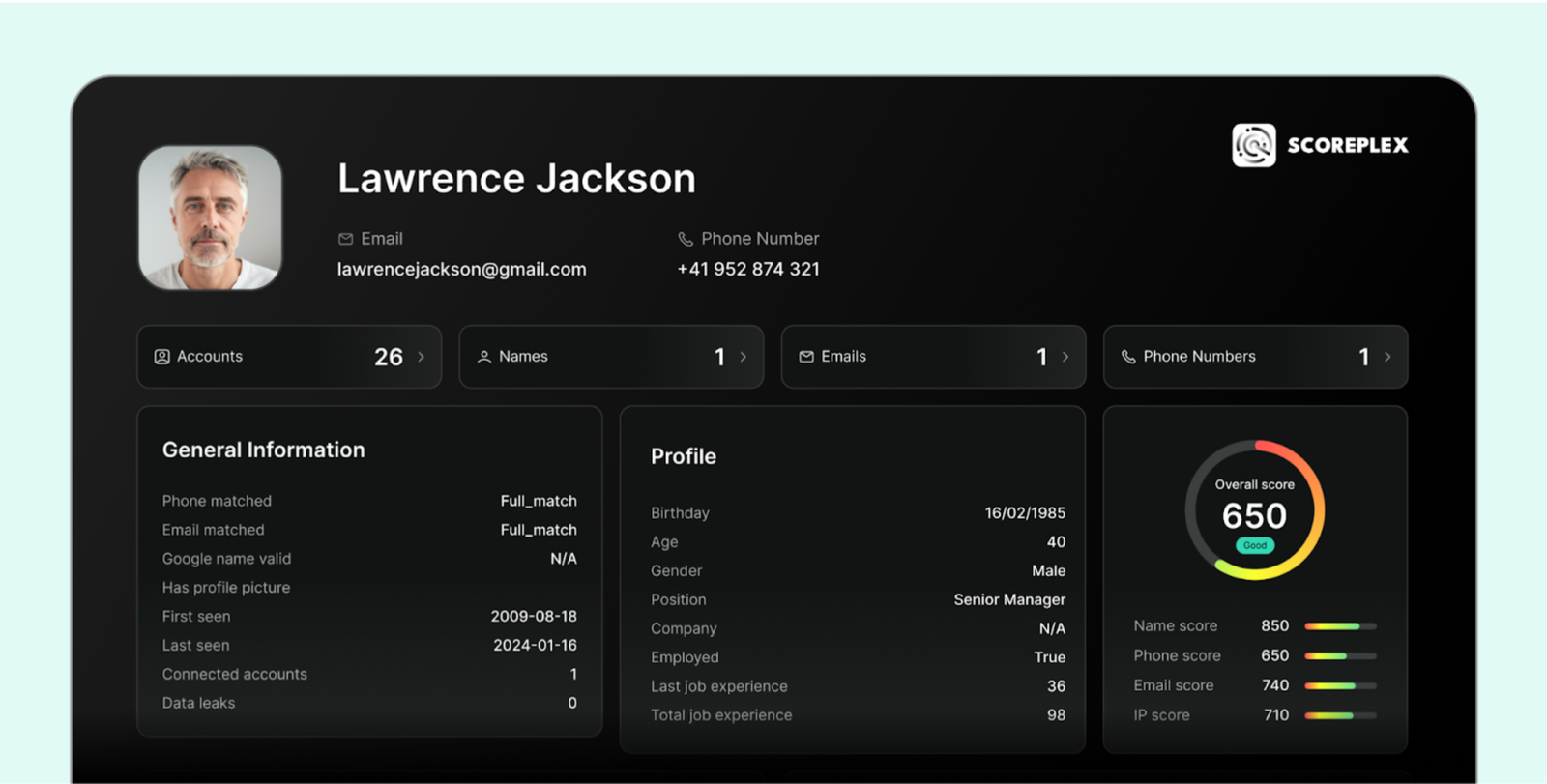
The Role of Scoring
One of the most effective ways to deliver insight is through email risk scoring. Instead of asking decision-makers to weigh dozens of signals manually, the system condenses them into a single score.
- HIGH (776–1000) Strong and consistent digital evidence of trustworthiness
- GOOD (551–775) Several positive signals detected
- MODERATE (451–550) Partial info available, uncertain identity
- BAD (226–450) Multiple negative signals present
- POOR (0–225): Likely spam, bot traffic, or synthetic identity
This doesn’t mean the underlying signals disappear. Transparency is crucial — especially in regulated industries like finance. But the score provides an instant decision framework, allowing platforms to scale without drowning in manual review.
Example: A crypto exchange integrates email scoring into its sign-up process. 70% of users pass with low scores, 20% go to secondary KYC, and 10% are blocked immediately. Fraud losses drop, while onboarding speed improves for real customers.
Turning Insight Into Action
The key challenge isn’t just deriving insight — it’s acting on it effectively. Businesses typically implement three types of workflows:
- Automatic acceptance: Low-risk users flow straight through, enjoying a smooth onboarding experience.
- Step-up verification: Medium-risk users are asked for extra checks — ID upload, phone verification, or manual review.
- Automatic rejection: High-risk users are blocked or reported before they can exploit the system.
By automating these workflows, companies can strike the right balance between security and user experience.
The Human Angle
At first glance, email intelligence might sound cold — algorithms scanning strings of text. But at its core, it’s about people.
- It protects a young professional from having their stolen identity used for fraud.
- It saves a small business from wasting ad spend on fake leads.
- It ensures a dating app user doesn’t fall prey to scammers.
Behind every signal, there’s a story. And behind every insight, there’s a human benefit.
Bringing It Together
Signals are the raw ingredients. Analysis provides the recipe. But insight is the meal — the part that truly feeds decision-making.
- A long-lived Gmail with connected accounts = trust.
- A disposable domain with no presence = risk.
- A mismatch with minor leaks = review needed.
This ability to translate technical signals into real-world meaning is why email intelligence is so valuable. It’s not about the data itself, but about the clarity it brings.
Challenges and Considerations
Email intelligence is powerful. It can stop fraud before it happens, protect customers from abuse, and save businesses millions. But with great power comes responsibility. The same signals that help identify risk can also raise difficult questions about fairness, accuracy, and transparency.
If businesses want to use email intelligence effectively — and sustainably — they need to acknowledge and address these challenges head-on.
- The Risk of False Positives
No intelligence system is perfect. Even the best models occasionally misclassify legitimate users as suspicious.
- Scenario: A genuine user registers with a brand-new Gmail address because they’ve just entered the workforce. The system sees “new domain usage” and “no connected accounts” and flags it as high risk.
- Impact: That user faces friction or rejection, damaging trust before the relationship even begins.
Mitigation:
- Use layered scoring instead of binary yes/no filters.
- Apply step-up verification (e.g., extra ID check) for medium-risk cases, rather than outright blocking.
- Continuously refine models to reduce false positives over time.
The goal is not just to block fraud, but to do so without alienating genuine customers.
- Regional and Cultural Differences
Not all markets behave the same way.
- In the U.S. and Europe, long-lived Gmail or Outlook accounts are the norm.
- In LATAM or APAC, it’s common for users to switch providers frequently, or to rely on regional services unfamiliar to global platforms.
Challenge: Signals that look “risky” in one region may be normal in another. For example, a short-lived domain might be suspicious in Germany but entirely standard in Indonesia.
Mitigation:
- Tailor risk models to regional baselines instead of applying global assumptions blindly.
- Continuously update datasets with local patterns and providers.
- Partner with regional experts to validate assumptions.
Without localization, email intelligence risks punishing the very populations who need fair access most — especially in emerging markets.
- Transparency vs. Black Box
Risk scores are useful, but they can feel opaque. If a customer is rejected, they may not understand why. If regulators ask, businesses must be able to explain.
- Challenge: Many scoring systems work like black boxes — great at classification, terrible at explanation.
- Impact: Lack of transparency erodes trust and invites regulatory scrutiny.
Mitigation:
- Provide reason codes with risk scores (e.g., “Domain disposable,” “Found in breaches,” “No connected accounts”).
- Use explainable AI techniques to show how signals contributed to the score.
- Educate customers and regulators on the principles of risk scoring.
Clarity builds confidence. When people understand decisions, they’re more likely to accept them.
- Balancing Security and User Experience
The constant tension: too much friction drives away good users, too little lets fraud slip through. Email intelligence helps strike the balance, but only if used thoughtfully.
- Overzealous blocking creates barriers to entry.
- Overly lenient scoring allows fraud to thrive.
Mitigation:
- Use adaptive workflows:
- Low risk → seamless onboarding.
- Medium risk → extra verification.
- High risk → block or escalate.
- Continuously monitor outcomes to ensure the balance is right.
The aim is to make the secure path also the easy path — so good users feel welcomed, not interrogated.
- Continuous Adaptation
Fraudsters evolve quickly. Disposable domains pop up daily. Attackers experiment with new naming conventions, new ways of hiding, new tools to mimic legitimacy. What looks “safe” today may be tomorrow’s loophole.
Mitigation:
- Treat email intelligence as a dynamic process, not a one-time setup.
- Regularly retrain models and refresh signal databases.
- Share intelligence across industries to stay ahead of new threats.
Email intelligence is not static. It must adapt constantly — both to fraud patterns and to changing expectations around fairness and transparency.
A Responsible Path Forward
The challenges of false positives, regional variation, transparency, user experience, and adaptation are real. But they are not roadblocks — they are guideposts. They remind us that email intelligence must be wielded with care, balancing protection, fairness, and trust.
For businesses, this means:
- Building models that are explainable, adaptable, and region-aware.
- Using intelligence not just to block risk, but to create smoother, safer experiences for genuine users.
Done right, email intelligence becomes more than a fraud filter. It becomes a trust engine — protecting platforms, empowering customers, and raising the bar for digital safety.
Conclusion: Why Email Intelligence Matters Now
Email addresses are everywhere. They are the keys to our online accounts, the front doors to digital services, the anchors of identity in a world where borders are blurred. For too long, they were treated as static fields on a form — a box to fill, not a signal to analyze.
The Stakes Are High
Fraudsters aren’t slowing down. They exploit speed, scale, and automation to slip into systems that rely on outdated checks. Traditional KYC and fraud prevention tools alone aren’t enough.
At the same time, customers are demanding smoother experiences. They expect instant onboarding, not paperwork. They expect safety, but not friction. Businesses must deliver both — and that’s only possible with smarter, more adaptive tools.
Email intelligence fills this gap. It filters out bad actors early, protects users from harm, and ensures that trustworthy customers enjoy a seamless path forward.
A Final Thought
Every fraudster needs an email. Every legitimate user has one too. The difference lies in the signals.
Businesses that ignore those signals expose themselves to fraud losses, wasted marketing spend, and broken customer trust. Businesses that embrace email intelligence gain an edge: lower fraud, higher efficiency, and a reputation for safety.
As digital ecosystems expand, email intelligence is becoming a core trust layer. And with the right approach — responsible, transparent, and adaptive — it can turn a string of characters into one of the most powerful identity anchors of our time.
Why Scoreplex?
In a crowded market of legacy fraud tools, Scoreplex was built with a different vision:
- Alternative data focus: Where others rely heavily on U.S. and EU-centric data, Scoreplex digs deeper into LATAM, APAC, and other high-risk, thin-file regions.
- Email as a primary signal: While most systems treat email as an afterthought, Scoreplex puts it at the center of its intelligence engine.
- Granular scoring: A 0–1000 risk score translates complex signals into clear, actionable outcomes — from auto-approve to step-up verification to auto-block.
- Future-ready design: AI-driven analysis, continuous updates, and regional adaptability keep the system one step ahead of fraudsters.
In short: Scoreplex doesn’t just check if an email exists. It reads the story behind it — and tells you whether to trust it.


